Following the wonderful feedback I got on my previous post (WordCloud in R – Mythological twist), I thought I could do a similar text analysis on the other great Indian Epic, the Mahabharata!
This time it is bigger, a 5818 page, 14 MB pdf. The translation in question is the original translation from Kisari Mohan Ganguli which was done sometime between 1883 and 1896.
About the Mahabharata
The Mahabharata is an epic narrative of the Kurukshetra War and the fates of the Kaurava and the Pandava princes.
The Mahabharata is the longest known epic poem and has been described as “the longest poem ever written”. Its longest version consists of over 100,000 shlokas or over 200,000 individual verse lines (each shloka is a couplet), and long prose passages. About 1.8 million words in total, the Mahabharata is roughly ten times the length of the Iliad and the Odyssey combined, or about four times the length of the Ramayana.
The first section of the Mahabharata states that it was Ganesha who wrote down the text to Vyasa’s dictation. Ganesha is said to have agreed to write it only if Vyasa never paused in his recitation. Vyasa agrees on condition that Ganesha takes the time to understand what was said before writing it down.
The Epic is divided into a total of 18 Parvas or Books.
Well, if Rama was at the centre of Ramayana, who was the equivalent in Mahabharata? Krishna? One of the Pandavas? One of the Kauravas? Dhritarashtra? Or one of the queens – Draupadi? Kunti? Gandhari?
Let us find out –
Since, this is a continuation to the first blog in this series, I would not take you through the intricacies of downloading and installing packages. Also, there is a Rpdf that needs to be installed, you could lookup on the instructions in this link.
Download and copy the pdf onto a folder in the local file system. You may want to read the pdf in its entirety to a corpus.
mahabharata <- Corpus(URISource(files), readerControl = list(reader = Rpdf))
If I look at the environment variables, I can see the Corpus populated, which says it has 1 element and is of a 26.8 MB size.
You could have a look at the details using ‘Inspect’

Now, we can begin processing this text, firstly create a content transformer to remove any take a value and replace it with white-space.
> toSpace <- content_transformer(function(x, pattern) {return (gsub(pattern, " ", x))})
use this to eliminate colons and hyphens
> mahabharata <- tm_map(mahabharata, toSpace, "-")
> mahabharata <- tm_map(mahabharata, toSpace, ":")
Next, we might need to apply some transformations on the text, to know the available transformations type getTransformations() in the R Console.
![]()
we would then need to convert all the text to lower case
> mahabharata <- tm_map(mahabharata, content_transformer(tolower))
let us also remove punctuation and numbers
> mahabharata <- tm_map(mahabharata, removePunctuation) > mahabharata <- tm_map(mahabharata, removeNumbers)
and the stopwords
> mahabharata <- tm_map(mahabharata, removeWords, stopwords("english"))
The next step would be to create a TermDocumentMatrix, a matrix that lists all the occurrences of words in the corpus. The DTM represents the documents as rows and the words as columns, if a word occurs in a particular document, the matrix entry corresponding to that row and column is 1 or it is a 0. Multiple occurrences are then added to the same count.
> dtm <- TermDocumentMatrix(mahabharata) > m <- as.matrix(dtm) > v <- sort(rowSums(m),decreasing=TRUE) > d <- data.frame(word = names(v),freq=v)

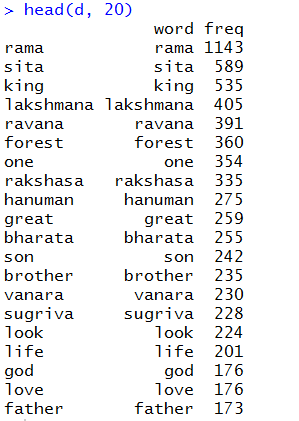
Looking at the frequencies of the words, we may need to remove certain words to distill the insights from the DTM, for e.g., words like “thou”, “thy”, “thee”, “can”, “one”, “the”, “and”, “like”…
> mahabharata <- tm_map(mahabharata, removeWords, c("the", "will", "like", "can"))
upon further refinement, let us look at the top 15 frequently appearing words
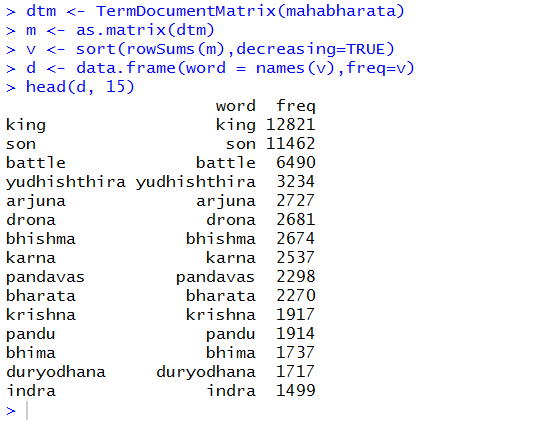
Brilliant, Isn’t it after all about a great battle between sons to be a King?!
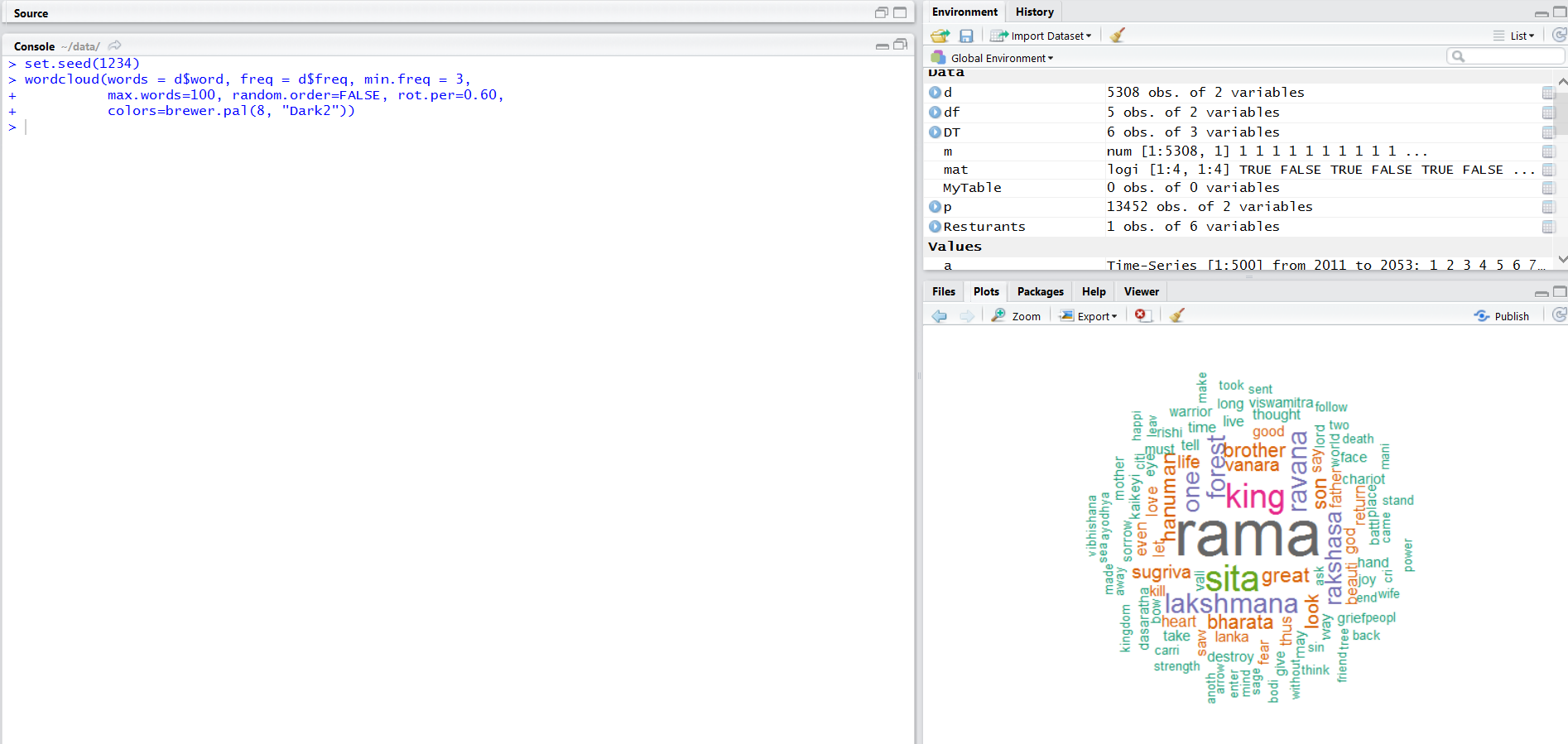
The next occurrences throw up some interesting observations.
- Yudhishthira
- Arjuna
- Drona
- Bhishma
- Karna
and Krishna, who is considered central to the Epic is at 8th of most mentioned characters in Mahabharata.
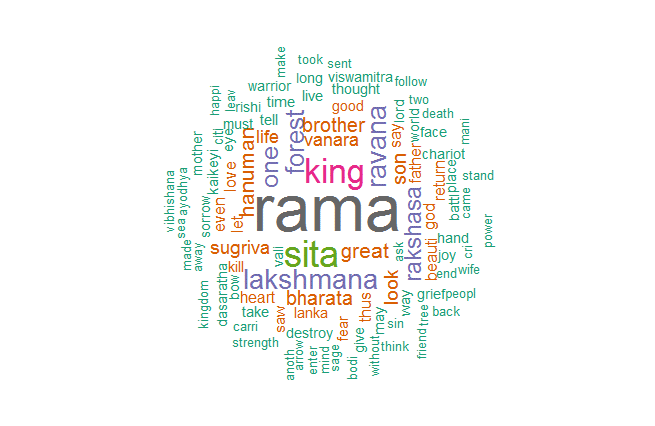
Let us generate the WordCloud from this