A WordCloud in R
Let Noble thoughts come to us from every side
– Rigveda, I-89-i
Have you ever wondered what it would be to do a textual analysis of some ancient texts? Would it not be nice to ‘mine’ insights into Valmiki’s Ramayana? Or Veda Vyasa’s Mahabharata? The Ramayana arguably happened about 9300 years ago. In the Thretha yuga. The wiki for Ramayana.
The original Ramayana consists of seven sections called kandas, these have varying numbers of chapters as follows: Bala-kanda—77 chapters, Ayodhya-kanda—119 chapters, Aranya-kanda—75 chapters, Kishkindha-kanda—67 chapters, Sundara-kanda—68 chapters, Yuddha-kanda—128 chapters, and Uttara-kanda—111 chapters.
So, there are a total of 24,000 verses in total. Well, I don’t really have the pdf of the ‘Original’ version, I thought I could use C. Rajagopalachari’s English retelling of the epic. This particular book is quiet popular and has sold over a million copies. It is a page-turner and has around 300 pages.

How about analyzing the text in this book?
Wouldn’t it be EPIC?!
That is exactly what I want to embark on this blog, text mining helps to derive valuable insights into the mind of the writer. It can also be leveraged to gain in-tangible insights like sentiment, relevance, mood, relations, emotion, summarization etc.
The first part of this series would be to run a descriptive analysis on the text and generate a word cloud. Tag clouds or word clouds add simplicity and clarity, the most used words are displayed as weighted averages, the more the count of the word, bigger would be the size of the word. After all, isn’t it visually engaging than looking at a table?
Firstly, we would need to install the relevant packages in R and load them –
The second step would be to read the pdf (which is currently in my working directory)
I first validate if the pdf is there in my working directory
![]()
The ‘tm’ package just provides a readPDF function, but the pdf engine needs to be downloaded. Let us use a pdf engine called xpdf. The link for setting up the pdf engine (and updating the system path) is here.
Great, now we can get rolling.
Let us create a pdf reader called ‘Rpdf’ using the code below, this instructs the pdftotext.exe to maintain the original physical layout of the text.
> Rpdf <- readPDF(control = list(text = "-layout"))
Now, we might need to convert the pdf to text and store it in a corpus. Basically we need to instruct the function on which resource we need to read. The second parameter is the reader that we created in the previous line.
> ramayana <- Corpus(URISource(files), readerControl = list(reader = Rpdf))
Now, let us check what the variable ‘ramayana’ contains
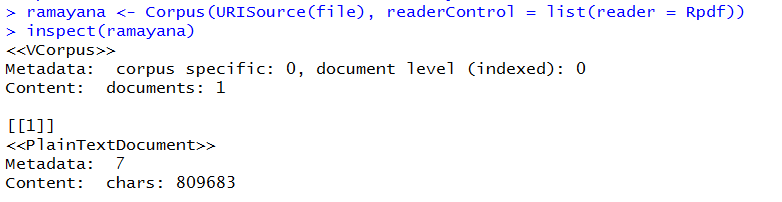
If I look at the summary of the variable, it will prompt me with the following details.

The next step would be to do some transformation on the text, let us use the tm_map() function is to replace special characters from the text. We could use this to replace single quotes (‘), full stops (.) and replace them with spaces.

Also, don’t you think we need to remove all the stop words? Words like ‘will’, ‘shall’, ‘the’, ‘we’ etc. do not make much sense in a word cloud. These are called stopwords, the tm_map provides for a function to do such an operation.
> ramayana <- tm_map(ramayana, removeWords, stopwords("english"))
Let us also convert all the text to lower
> ramayana <- tm_map(ramayana, content_transformer(tolower))
I could also specify some stop-words that I would want to remove using the code:
> ramayana <- tm_map(ramayana, removeWords, c("the", "will", "like", "can", "and", "shall"))
Let us also remove white spaces and remove the punctuation.
> ramayana <- tm_map(ramayana, removePunctuation)
> ramayana <- tm_map(ramayana, stripWhitespace)
Any other pre-processing that you can think of? How about removing suffixes, removing tense in words? Is ‘kill’ different from ‘killed’? Do they not originate from the same stem ‘kill’? Or ‘big’, ‘bigger’, ‘biggest’? Can’t we just have ‘big’ with a weight of 3 instead of these three separate words? We use the stemDocument parameter for this.
> ramayana <- tm_map(ramayana, stemDocument)
The next step would be to create a term-document matrix. It is a table containing the frequency of words. We use ‘termdocumentmatrix’ provided by the text mining package to do this.
> dtm <- TermDocumentMatrix(ramayana) > m <- as.matrix(dtm) > v <- sort(rowSums(m),decreasing=TRUE) > d <- data.frame(word = names(v),freq=v)
Now, let us look at a sample of the words and their frequency we got. We pick the first 20.
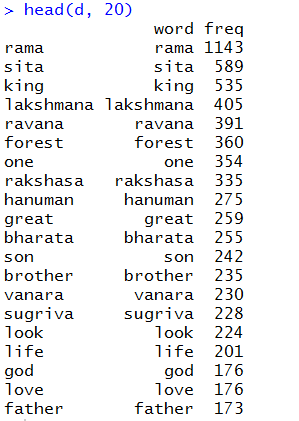
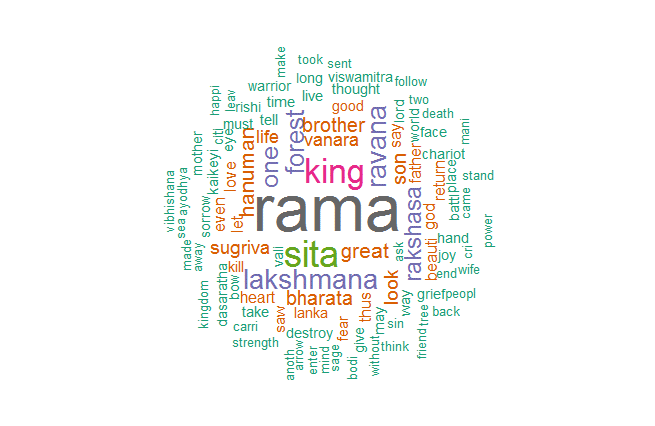
Not surprising, is it? ‘Rama’ is indeed the centre of the story.
Now, let us generate the word cloud
> wordcloud(words = d$word, freq = d$freq, min.freq = 3, max.words=100, random.order=FALSE, rot.per=0.60, colors=brewer.pal(8, "Dark2"))
Voila! The word cloud of all the words of Ramayana.
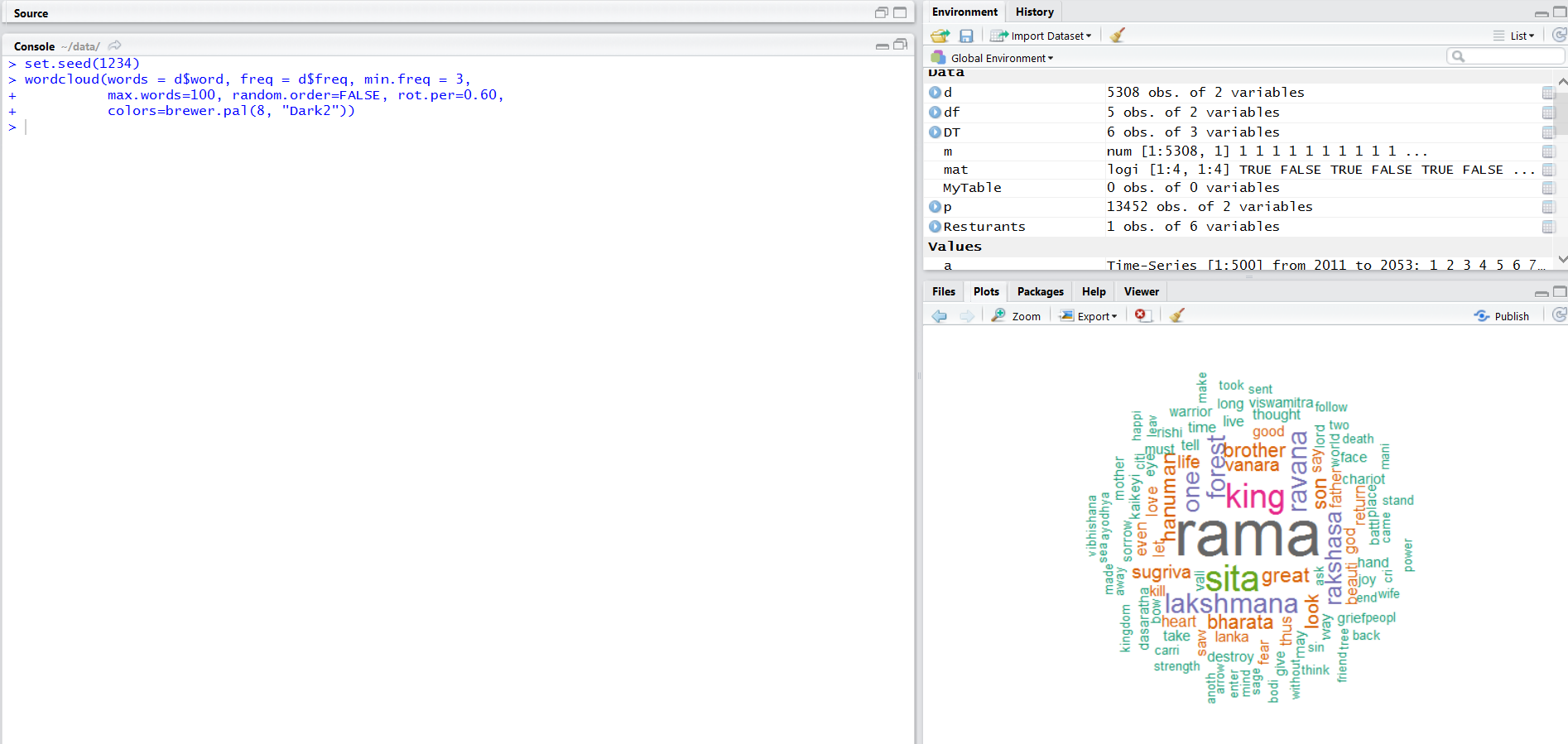
A view of plot downloaded from R.
If you like this, you could comment below. If you would like to connect with me, then be sure to find me on Twitter, Facebook, LinkedIn. The links are on the side navigation. Or you could drop an email to shivdeep.envy@gmail.com
excellent analysis depicting the power of R!
Keep the blogs coming Shivdeep!